")
The synthesis of proteins consumes more of a cell’s energy than any other metabolic process. In turn, proteins account for more mass than any other macromolecule of living organisms. They perform virtually every function of a cell, serving as both functional (e.g., enzymes) and structural elements. The process of translation, or protein synthesis, the second part of gene expression, involves the decoding by a ribosome of an mRNA message into a polypeptide product.
Translation of the mRNA template converts nucleotide-based genetic information into the “language” of amino acids to create a protein product. A protein sequence consists of 20 commonly occurring amino acids. Each amino acid is defined within the mRNA by a triplet of nucleotides called a codon. The relationship between an mRNA codon and its corresponding amino acid is called the genetic code.
The three-nucleotide code means that there is a total of 64 possible combinations (43, with four different nucleotides possible at each of the three different positions within the codon). This number is greater than the number of amino acids and a given amino acid is encoded by more than one codon ([link]). This redundancy in the genetic code is called degeneracy. Typically, whereas the first two positions in a codon are important for determining which amino acid will be incorporated into a growing polypeptide, the third position, called the wobble position, is less critical. In some cases, if the nucleotide in the third position is changed, the same amino acid is still incorporated.
Whereas 61 of the 64 possible triplets code for amino acids, three of the 64 codons do not code for an amino acid; they terminate protein synthesis, releasing the polypeptide from the translation machinery. These are called stop codons or nonsense codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also typically serves as the start codon to initiate translation. The reading frame, the way nucleotides in mRNA are grouped into codons, for translation is set by the AUG start codon near the 5’ end of the mRNA. Each set of three nucleotides following this start codon is a codon in the mRNA message.
The genetic code is nearly universal. With a few exceptions, virtually all species use the same genetic code for protein synthesis, which is powerful evidence that all extant life on earth shares a common origin. However, unusual amino acids such as selenocysteine and pyrrolysine have been observed in archaea and bacteria. In the case of selenocysteine, the codon used is UGA (normally a stop codon). However, UGA can encode for selenocysteine using a stem-loop structure (known as the selenocysteine insertion sequence, or SECIS element), which is found at the 3’ untranslated region of the mRNA. Pyrrolysine uses a different stop codon, UAG. The incorporation of pyrrolysine requires the pylS gene and a unique transfer RNA (tRNA) with a CUA anticodon.
In addition to the mRNA template, many molecules and macromolecules contribute to the process of translation. The composition of each component varies across taxa; for instance, ribosomes may consist of different numbers of ribosomal RNAs (rRNAs) and polypeptides depending on the organism. However, the general structures and functions of the protein synthesis machinery are comparable from bacteria to human cells. Translation requires the input of an mRNA template, ribosomes, tRNAs, and various enzymatic factors.
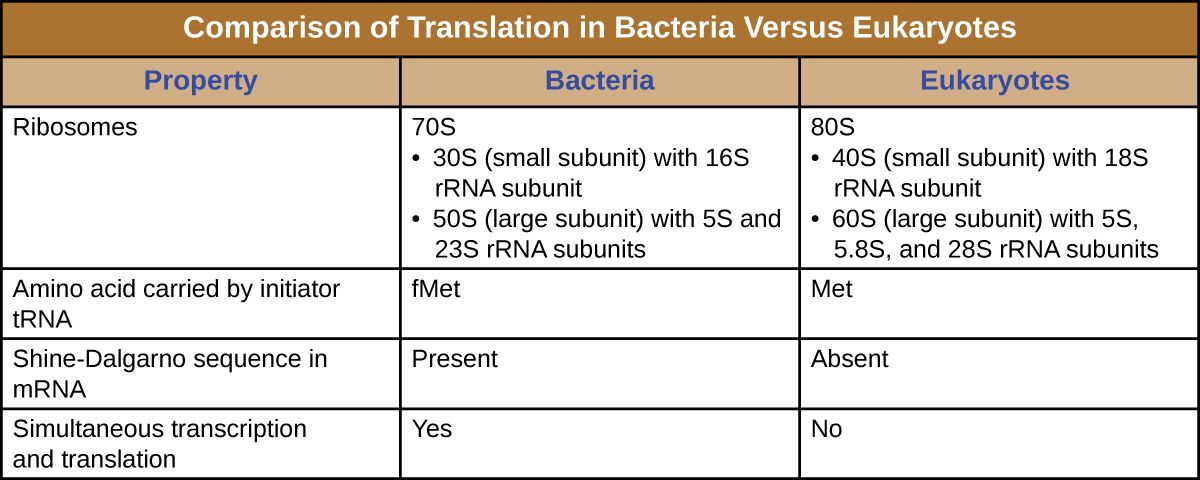
A ribosome is a complex macromolecule composed of catalytic rRNAs (called ribozymes) and structural rRNAs, as well as many distinct polypeptides. Mature rRNAs make up approximately 50% of each ribosome. Prokaryotes have 70S ribosomes, whereas eukaryotes have 80S ribosomes in the cytoplasm and rough endoplasmic reticulum, and 70S ribosomes in mitochondria and chloroplasts. Ribosomes dissociate into large and small subunits when they are not synthesizing proteins and reassociate during the initiation of translation. In E. coli, the small subunit is described as 30S (which contains the 16S rRNA subunit), and the large subunit is 50S (which contains the 5S and 23S rRNA subunits), for a total of 70S (Svedberg units are not additive). Eukaryote ribosomes have a small 40S subunit (which contains the 18S rRNA subunit) and a large 60S subunit (which contains the 5S, 5.8S and 28S rRNA subunits), for a total of 80S. The small subunit is responsible for binding the mRNA template, whereas the large subunit binds tRNAs (discussed in the next subsection).
Each mRNA molecule is simultaneously translated by many ribosomes, all synthesizing protein in the same direction: reading the mRNA from 5’ to 3’ and synthesizing the polypeptide from the N terminus to the C terminus. The complete structure containing an mRNA with multiple associated ribosomes is called a polyribosome (or polysome). In both bacteria and archaea, before transcriptional termination occurs, each protein-encoding transcript is already being used to begin synthesis of numerous copies of the encoded polypeptide(s) because the processes of transcription and translation can occur concurrently, forming polyribosomes ([link]). The reason why transcription and translation can occur simultaneously is because both of these processes occur in the same 5’ to 3’ direction, they both occur in the cytoplasm of the cell, and because the RNA transcript is not processed once it is transcribed. This allows a prokaryotic cell to respond to an environmental signal requiring new proteins very quickly. In contrast, in eukaryotic cells, simultaneous transcription and translation is not possible. Although polyribosomes also form in eukaryotes, they cannot do so until RNA synthesis is complete and the RNA molecule has been modified and transported out of the nucleus.

Transfer RNAs (tRNAs) are structural RNA molecules and, depending on the species, many different types of tRNAs exist in the cytoplasm. Bacterial species typically have between 60 and 90 types. Serving as adaptors, each tRNA type binds to a specific codon on the mRNA template and adds the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins. As the adaptor molecules of translation, it is surprising that tRNAs can fit so much specificity into such a small package. The tRNA molecule interacts with three factors: aminoacyl tRNA synthetases, ribosomes, and mRNA.
Mature tRNAs take on a three-dimensional structure when complementary bases exposed in the single-stranded RNA molecule hydrogen bond with each other ([link]). This shape positions the amino-acid binding site, called the CCA amino acid binding end, which is a cytosine-cytosine-adenine sequence at the 3’ end of the tRNA, and the anticodon at the other end. The anticodon is a three-nucleotide sequence that bonds with an mRNA codon through complementary base pairing.
An amino acid is added to the end of a tRNA molecule through the process of tRNA “charging,” during which each tRNA molecule is linked to its correct or cognate amino acid by a group of enzymes called aminoacyl tRNA synthetases. At least one type of aminoacyl tRNA synthetase exists for each of the 20 amino acids. During this process, the amino acid is first activated by the addition of adenosine monophosphate (AMP) and then transferred to the tRNA, making it a charged tRNA, and AMP is released.
 After folding caused by intramolecular base pairing, a tRNA molecule has one end that contains the anticodon, which interacts with the mRNA codon, and the CCA amino acid binding end. (b) A space-filling model is helpful for visualizing the three-dimensional shape of tRNA. (c) Simplified models are useful when drawing complex processes such as protein synthesis.")
Translation is similar in prokaryotes and eukaryotes. Here we will explore how translation occurs in E. coli, a representative prokaryote, and specify any differences between bacterial and eukaryotic translation.
The initiation of protein synthesis begins with the formation of an initiation complex. In E. coli, this complex involves the small 30S ribosome, the mRNA template, three initiation factors that help the ribosome assemble correctly, guanosine triphosphate (GTP) that acts as an energy source, and a special initiator tRNA carrying N-formyl-methionine (fMet-tRNAfMet) ([link]). The initiator tRNA interacts with the start codon AUG of the mRNA and carries a formylated methionine (fMet). Because of its involvement in initiation, fMet is inserted at the beginning (N terminus) of every polypeptide chain synthesized by E. coli. In E. coli mRNA, a leader sequence upstream of the first AUG codon, called the Shine-Dalgarno sequence (also known as the ribosomal binding site AGGAGG), interacts through complementary base pairing with the rRNA molecules that compose the ribosome. This interaction anchors the 30S ribosomal subunit at the correct location on the mRNA template. At this point, the 50S ribosomal subunit then binds to the initiation complex, forming an intact ribosome.
In eukaryotes, initiation complex formation is similar, with the following differences:

In prokaryotes and eukaryotes, the basics of elongation of translation are the same. In E. coli, the binding of the 50S ribosomal subunit to produce the intact ribosome forms three functionally important ribosomal sites: The A (aminoacyl) site binds incoming charged aminoacyl tRNAs. The P (peptidyl) site binds charged tRNAs carrying amino acids that have formed peptide bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA. The E (exit) site releases dissociated tRNAs so that they can be recharged with free amino acids. There is one notable exception to this assembly line of tRNAs: During initiation complex formation, bacterial fMet−tRNAfMet or eukaryotic Met-tRNAi enters the P site directly without first entering the A site, providing a free A site ready to accept the tRNA corresponding to the first codon after the AUG.
Elongation proceeds with single-codon movements of the ribosome each called a translocation event. During each translocation event, the charged tRNAs enter at the A site, then shift to the P site, and then finally to the E site for removal. Ribosomal movements, or steps, are induced by conformational changes that advance the ribosome by three bases in the 3’ direction. Peptide bonds form between the amino group of the amino acid attached to the A-site tRNA and the carboxyl group of the amino acid attached to the P-site tRNA. The formation of each peptide bond is catalyzed by peptidyl transferase, an RNA-based ribozyme that is integrated into the 50S ribosomal subunit. The amino acid bound to the P-site tRNA is also linked to the growing polypeptide chain. As the ribosome steps across the mRNA, the former P-site tRNA enters the E site, detaches from the amino acid, and is expelled. Several of the steps during elongation, including binding of a charged aminoacyl tRNA to the A site and translocation, require energy derived from GTP hydrolysis, which is catalyzed by specific elongation factors. Amazingly, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200 amino-acid protein can be translated in just 10 seconds.
The termination of translation occurs when a nonsense codon (UAA, UAG, or UGA) is encountered for which there is no complementary tRNA. On aligning with the A site, these nonsense codons are recognized by release factors in prokaryotes and eukaryotes that result in the P-site amino acid detaching from its tRNA, releasing the newly made polypeptide. The small and large ribosomal subunits dissociate from the mRNA and from each other; they are recruited almost immediately into another translation initiation complex.
In summary, there are several key features that distinguish prokaryotic gene expression from that seen in eukaryotes. These are illustrated in [link] and listed in [link].
 In prokaryotes, the processes of transcription and translation occur simultaneously in the cytoplasm, allowing for a rapid cellular response to an environmental cue. (b) In eukaryotes, transcription is localized to the nucleus and translation is localized to the cytoplasm, separating these processes and necessitating RNA processing for stability.")
During and after translation, polypeptides may need to be modified before they are biologically active. Post-translational modifications include:
Which of the following is the name of the three-base sequence in the mRNA that binds to a tRNA molecule?
B
Which component is the last to join the initiation complex during the initiation of translation?
C
During elongation in translation, to which ribosomal site does an incoming charged tRNA molecule bind?
A
Which of the following is the amino acid that appears at the N-terminus of all newly translated prokaryotic and eukaryotic polypeptides?
B
When the ribosome reaches a nonsense codon, which of the following occurs?
B
The third position within a codon, in which changes often result in the incorporation of the same amino acid into the growing polypeptide, is called the ________.
wobble position
The enzyme that adds an amino acid to a tRNA molecule is called ________.
aminoacyl-tRNA synthetase
Each codon within the genetic code encodes a different amino acid.
False
Why does translation terminate when the ribosome reaches a stop codon? What happens?
How does the process of translation differ between prokaryotes and eukaryotes?
What is meant by the genetic code being nearly universal?
Below is an antisense DNA sequence. Translate the mRNA molecule synthesized using the genetic code, recording the resulting amino acid sequence, indicating the N and C termini.
Antisense DNA strand: 3’-T A C T G A C T G A C G A T C-5’
Label the following in the figure: ribosomal E, P, and A sites; mRNA; codons; anticodons; growing polypeptide; incoming amino acid; direction of translocation; small ribosomal unit; large ribosomal unit.
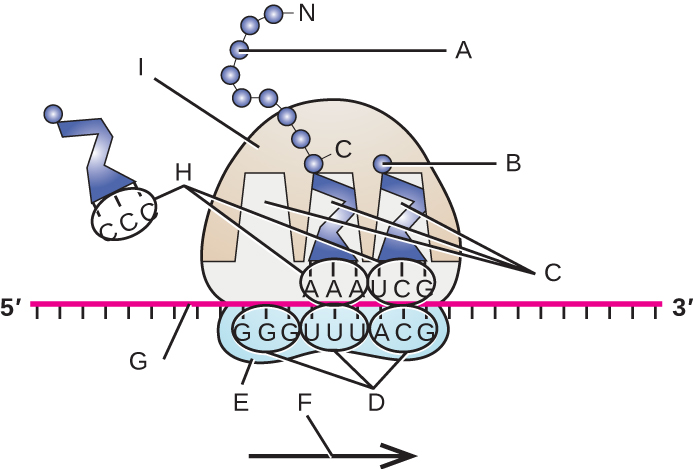
Prior to the elucidation of the genetic code, prominent scientists, including Francis Crick, had predicted that each mRNA codon, coding for one of the 20 amino acids, needed to be at least three nucleotides long. Why is it not possible for codons to be any shorter?

You can also download for free at http://cnx.org/contents/e42bd376-624b-4c0f-972f-e0c57998e765@5.3
Attribution: